
Few days ago I was trying to purchase an item in Amazon. Looking at the reviews , I was wondering how can we classify them as good vs bad using machine learning on texts. Neither do I have a labelled corpus to train a supervised algorithm nor I was able to find a pre-trained model to do a transfer learning.
With some research , today I want to discuss few techniques helpful for unsupervised text classification in python. Mainly , LDA ( Latent Derilicht Analysis ) & NMF ( Non-negative Matrix factorization )
1. Latent Derilicht Analysis ( LDA ) Conquered
LDA is widely based on probability distributions. Firstly it was published as a paper for graphical models for topic discovery in the year 2003 by Andrew ng and his team. You may read the paper HERE.
I can understand you either skipped the research paper or opened it and just had a glance 😛 Thats Okay.
We shall now discuss few necessary points regarding LDA which are to be remembered.
LDA assumes :
- Documents with similar topics will always have similar set of words.
- Groups are formed by searching group of words that frequently appear in document.
- User has to input/provide the value of ‘ K ‘ i.e number of topics in a document.
- Documents are assumed to be probability distributions over topics.
- Topics are assumed to be probability distributions over words used in documents.
Okay last 2 points may be slight hard to digest , but you can remember LDA majorly with first 2 points above.
A sneak through on how LDA works is , assume we have a topic fashion. For a word ‘ saree ‘ , the words ‘ dress ‘ , ‘ pants ‘ will have higher probability of being closer than words ‘ monday ‘ , ‘ rain ‘ etc.
Now let’s look at how LDA works step by step for unsupervised text classification.
1.1 How Does LDA Work ?
Note : As we discussed above ( Bullet point number 3 ), User has to have an idea on how many categories of text are in a document. Once then , we decide the value of K i.e number of topics in a document , and then LDA proceeds as below for unsupervised Text Classification:
- Go through each document , and randomly assign each word a cluster K.
- For every word in a document D of a topic T , the portion of words assigned are calculated. i.e p( T/D ).
- For every word in a document D of a topic T , the portion of words W assigned to a topic T are calculated. i.e p( W/T ).
- Reassign word W a new topic where we choose topic T with probability p( T/D ) * p( W/T ).
- Steps are repeated until results converge.
After completion , We would have K clusters of topics. It’s upto us to understand the words in each cluster and assign a category.
Let’s implement LDA and understand what did we mean by assign a category.
1.2 LDA In Action
Download the Input file Here.
'''
Important modules + read data
'''
import pandas as pd
npr = pd.read_csv('npr.csv')
npr.head()

We apply a count vectoriser to represent text as numbers as any algorithms expect 😛
max_df: float in range [0.0, 1.0] or int, default=1.0
When building the vocabulary ignore terms that have a document frequency strictly higher than the given threshold (corpus-specific stop words). If float, the parameter represents a proportion of documents, integer absolute counts. This parameter is ignored if vocabulary is not None.
min_df: float in range [0.0, 1.0] or int, default=1
When building the vocabulary ignore terms that have a document frequency strictly lower than the given threshold. This value is also called cut-off in the literature. If float, the parameter represents a proportion of documents, integer absolute counts. This parameter is ignored if vocabulary is not None.
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(max_df=0.95, min_df=2, stop_words='english')
dtm = cv.fit_transform(npr['Article'])
dtm
<11992x54777 sparse matrix of type '<class 'numpy.int64'>'
with 3033388 stored elements in Compressed Sparse Row format>
We import the LDA from sklearn and define the number of clusters i.e n_components = 7
from sklearn.decomposition import LatentDirichletAllocation
LDA = LatentDirichletAllocation(n_components=7,random_state=42)
LDA.fit(dtm)
LatentDirichletAllocation(batch_size=128, doc_topic_prior=None,
evaluate_every=-1, learning_decay=0.7,
learning_method='batch', learning_offset=10.0,
max_doc_update_iter=100, max_iter=10, mean_change_tol=0.001,
n_components=7, n_jobs=None, n_topics=None, perp_tol=0.1,
random_state=42, topic_word_prior=None,
total_samples=1000000.0, verbose=0)
Lets display few words and counts.
import random
for i in range(10):
random_word_id = random.randint(0,54776)
print(cv.get_feature_names()[random_word_id])
cred
fairly
occupational
temer
tamil
closest
condone
breathes
tendrils
pivot
Let’s display the top 15 words in each 7 clusters we defined.
for index,topic in enumerate(LDA.components_):
print(f'THE TOP 15 WORDS FOR TOPIC #{index}')
print([cv.get_feature_names()[i] for i in topic.argsort()[-15:]])
print('\n')
THE TOP 15 WORDS FOR TOPIC #0
['companies', 'money', 'year', 'federal', '000', 'new', 'percent', 'government', 'company', 'million', 'care', 'people', 'health', 'said', 'says']
THE TOP 15 WORDS FOR TOPIC #1
['military', 'house', 'security', 'russia', 'government', 'npr', 'reports', 'says', 'news', 'people', 'told', 'police', 'president', 'trump', 'said']
THE TOP 15 WORDS FOR TOPIC #2
['way', 'world', 'family', 'home', 'day', 'time', 'water', 'city', 'new', 'years', 'food', 'just', 'people', 'like', 'says']
THE TOP 15 WORDS FOR TOPIC #3
['time', 'new', 'don', 'years', 'medical', 'disease', 'patients', 'just', 'children', 'study', 'like', 'women', 'health', 'people', 'says']
THE TOP 15 WORDS FOR TOPIC #4
['voters', 'vote', 'election', 'party', 'new', 'obama', 'court', 'republican', 'campaign', 'people', 'state', 'president', 'clinton', 'said', 'trump']
THE TOP 15 WORDS FOR TOPIC #5
['years', 'going', 've', 'life', 'don', 'new', 'way', 'music', 'really', 'time', 'know', 'think', 'people', 'just', 'like']
THE TOP 15 WORDS FOR TOPIC #6
['student', 'years', 'data', 'science', 'university', 'people', 'time', 'schools', 'just', 'education', 'new', 'like', 'students', 'school', 'says']
Similar to clustering techniques , we add the cluster number to original dataframe.
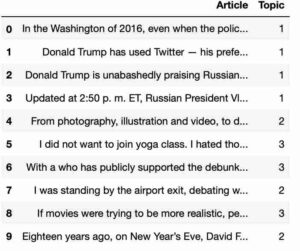
topic_results = LDA.transform(dtm)
npr['Topic'] = topic_results.argmax(axis=1)
npr.head(10)
1.3 Assigning Cluster names
Observe top words above from cluster 0-6 and try to assign a category depending on words.
Ex. : Topic 1 has words more related to government followed by topic 2 about security and so on.
We assign categories manually , sheerly based on observing words and our instinct of identifying the categories.
We can create a dictionary of mappings based on our instinct and then apply to the dataframe as below.
myDict = {0 : 'govt' , 1 : 'security', 2 : 'calender', 3 : 'medical',4 : 'US politics' , 5 : 'life' , 6 : 'education'}
npr['category'] = npr['topics'].map(myDict)
Phew ! We should have our unstructured data labelled now i.e unsupervised text been classified successfully.
1.4 Complete Code
import pandas as pd
npr = pd.read_csv('npr.csv')
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(max_df=0.95, min_df=2, stop_words='english')
dtm = cv.fit_transform(npr['Article'])
from sklearn.decomposition import LatentDirichletAllocation
LDA = LatentDirichletAllocation(n_components=7,random_state=42)
LDA.fit(dtm)
import random
for i in range(10):
random_word_id = random.randint(0,54776)
print(cv.get_feature_names()[random_word_id])
top_word_indices = single_topic.argsort()[-10:]
for index in top_word_indices:
print(cv.get_feature_names()[index])
for index,topic in enumerate(LDA.components_):
print(f'THE TOP 15 WORDS FOR TOPIC #{index}')
print([cv.get_feature_names()[i] for i in topic.argsort()[-15:]])
print('\n')
topic_results = LDA.transform(dtm)
npr['topics'] = topic_results.argmax(axis=1)
#we decide this based on the clusters and our instinct. Read post for more info.
myDict = {0 : 'govt' , 1 : 'security', 2 : 'calender', 3 : 'medical',4 : 'US politics' , 5 : 'life' , 6 : 'education'}
npr['category'] = npr['topics'].map(myDict)
npr.head(10)
2. Non-negative Matrix factorization ( NMF) Conquered
Non-negative Matrix factorization is an unsupervised algorithm that performs dimensionality reduction and clustering simultaneously. The research paper for NMF is available here. Feel free to explore !
NMF is useful when there are large number of attributes and the attributes are ambiguous or have weak predictability.
NMF works by combining attributes and produces meaningful patterns, topics, or categories which is essential for accurate predictions.
Non-negative Matrix factorization breaks down data matrix V to the product of two lower rank matrices W and H so that V is nearly similar to W times H.
NMF uses iterative process to modify the initial values of W and H so that the product approaches V.
The procedure iterates and then ends when the approximation error converges or the specified number of iterations are reached.
2.1 How To Implement NMF ?
These steps sum up how do we implement non-negative Matrix factorization in python.

2.2 Final Outcome after NMF Evaluates texts in docs.
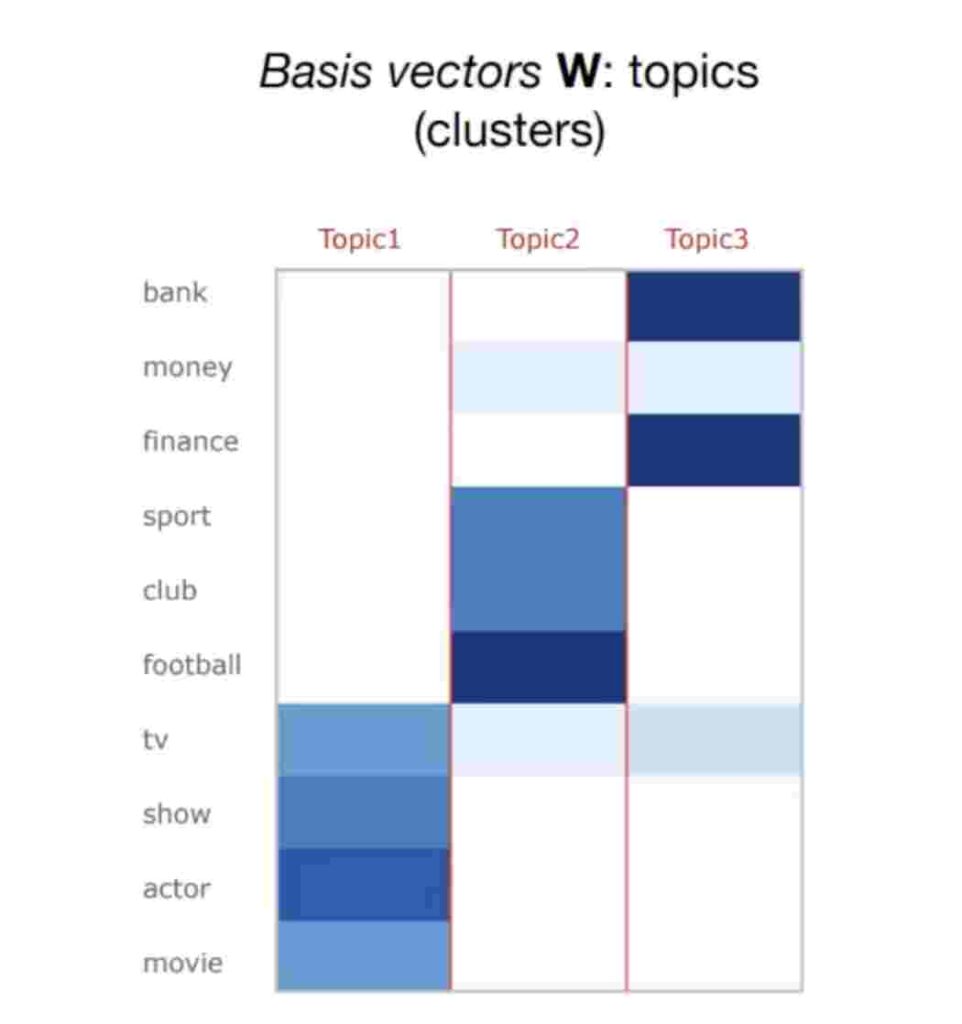
The outcome of NMF will mainly have 2 entities. 1 : Basis vectors W 2 : Coefficients H
1 : Basis vectors – The colouring tells us how relevant specific word is for a topic .
2 : Coefficients – The colouring tells us how relevant documents are to the topics .

2.3 Few pointers to remember when implementing NMF
- Similar to LDA User has to input/provide the value of ‘ K ‘ i.e number of topics in a document.
- Once the algorithm create clusters , its upto user discretion to assign clusters a name.
2.4 NMF In Action
Download the Input file Here.
The implementation is pretty similar to LDA except for we use NMF here.
import pandas as pd
npr = pd.read_csv('npr.csv')
npr.head()
'''
Preprocessing using term frequency - inverse document frequency.
'''
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(max_df=0.95, min_df=2, stop_words='english')
dtm = tfidf.fit_transform(npr['Article'])
'''
We import NMF module here
We also specify number of clusters i.e n_clusters = 7
'''
from sklearn.decomposition import NMF
nmf_model = NMF(n_components=7,random_state=42)
nmf_model.fit(dtm)
print("record size : ",len(tfidf.get_feature_names()))
NMF(alpha=0.0, beta_loss='frobenius', init=None, l1_ratio=0.0, max_iter=200,
n_components=7, random_state=42, shuffle=False, solver='cd', tol=0.0001,
verbose=0)
record size : 54777
We display few random values words for a specific topics.
import random
for i in range(10):
random_word_id = random.randint(0,54776)
print(tfidf.get_feature_names()[random_word_id])
distinctively
pointless
28th
trinity
andes
loren
florence
bioterrorists
bolstering
typeface
We display top 15 words for every topic assigned by the NMF algorithm.
for index,topic in enumerate(nmf_model.components_):
print(f'THE TOP 15 WORDS FOR TOPIC #{index}')
print([tfidf.get_feature_names()[i] for i in topic.argsort()[-15:]])
print('\n')
THE TOP 15 WORDS FOR TOPIC #0
['new', 'research', 'like', 'patients', 'health', 'disease', 'percent', 'women', 'virus', 'study', 'water', 'food', 'people', 'zika', 'says']
THE TOP 15 WORDS FOR TOPIC #1
['gop', 'pence', 'presidential', 'russia', 'administration', 'election', 'republican', 'obama', 'white', 'house', 'donald', 'campaign', 'said', 'president', 'trump']
THE TOP 15 WORDS FOR TOPIC #2
['senate', 'house', 'people', 'act', 'law', 'tax', 'plan', 'republicans', 'affordable', 'obamacare', 'coverage', 'medicaid', 'insurance', 'care', 'health']
THE TOP 15 WORDS FOR TOPIC #3
['officers', 'syria', 'security', 'department', 'law', 'isis', 'russia', 'government', 'state', 'attack', 'president', 'reports', 'court', 'said', 'police']
THE TOP 15 WORDS FOR TOPIC #4
['primary', 'cruz', 'election', 'democrats', 'percent', 'party', 'delegates', 'vote', 'state', 'democratic', 'hillary', 'campaign', 'voters', 'sanders', 'clinton']
THE TOP 15 WORDS FOR TOPIC #5
['love', 've', 'don', 'album', 'way', 'time', 'song', 'life', 'really', 'know', 'people', 'think', 'just', 'music', 'like']
THE TOP 15 WORDS FOR TOPIC #6
['teacher', 'state', 'high', 'says', 'parents', 'devos', 'children', 'college', 'kids', 'teachers', 'student', 'education', 'schools', 'school', 'students']
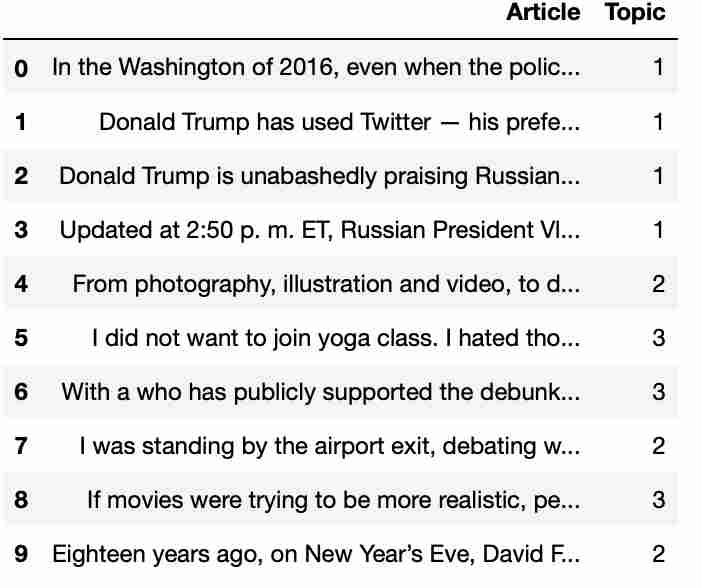
Assign topics back to data frames.
topic_results = nmf_model.transform(dtm)
npr['Topic'] = topic_results.argmax(axis=1)
npr.head(10)
2.5 Assigning Cluster names
As in LDA Observe top words above from cluster 0-6 and try to assign a category depending on words.
Ex. : Topic 1 has words more related to government followed by topic 2 about security and so on.
We assign categories manually , sheerly based on observing words and our instinct of identifying the categories.
We can create a dictionary of mappings based on our instinct and then apply to the dataframe as below.
myDict = {0 : 'medical' , 1 : 'admin', 2 : 'money', 3 : 'law',4 : 'US politics' , 5 : 'life' , 6 : 'education'}
npr['category'] = npr['topics'].map(myDict)
2.6 Complete Code
import pandas as pd
npr = pd.read_csv('npr.csv')
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(max_df=0.95, min_df=2, stop_words='english')
dtm = tfidf.fit_transform(npr['Article'])
from sklearn.decomposition import NMF
nmf_model = NMF(n_components=7,random_state=42)
nmf_model.fit(dtm)
for index,topic in enumerate(nmf_model.components_):
print(f'THE TOP 15 WORDS FOR TOPIC #{index}')
print([tfidf.get_feature_names()[i] for i in topic.argsort()[-15:]])
print('\n')
topic_results = nmf_model.transform(dtm)
npr['topics'] = topic_results.argmax(axis=1)
myDict = {0 : 'medical' , 1 : 'admin', 2 : 'money', 3 : 'law',4 : 'US politics' , 5 : 'life' , 6 : 'education'}
npr['category'] = npr['topics'].map(myDict)
npr.head(10)
Phew ! We warp this up well.
3. Final Say
We majorly covered 2 major ways to manage unsupervised texts and how to bring them under certain categories.
While there is no clear winner between LDA and NMF , certain research says NMF works better.
End of the day its upto our test case and trail and error to finalise on which technique work out better.
Thanks for reading!
You may not want to miss these exciting posts :
- Hashing In Python From Scratch ( Code Included )
 We cover hashing in python from scratch. Data strutures like dictionary in python use underlying logic of hashing which we discuss in detail.
We cover hashing in python from scratch. Data strutures like dictionary in python use underlying logic of hashing which we discuss in detail. - Recursion In Python With Examples | MemoizationThis article covers Recursion in Python and Memoization in Python. Recursion is explained with real world examples.
- Unsupervised Text Classification In PythonUnsupervised text classification using python using LDA ( Latent Derilicht Analysis ) & NMF ( Non-negative Matrix factorization )
- Unsupervised Sentiment Analysis Using PythonThis artilce explains unsupervised sentiment analysis using python. Using NLTK VADER to perform sentiment analysis on non labelled data.
- Data Structures In Python – Stacks , Queues & DequesData structures series in python covering stacks in python , queues in python and deque in python with thier implementation from scratch.




