
Recently , the company I worked for saw a huge churn in customers due to some user experience issues.
We hence decided to collect feedbacks from all the customers and analyse their sentiments. The problem is , we do not have any past labelled data to train a model and predict on current feedbacks.
Although most of the analysis over the web concentrates on supervised sentiment analysis. We today will checkout unsupervised sentiment analysis using python.
As we all know , supervised analysis involves building a trained model and then predicting the sentiments. This needs considerably lot of data to cover all the possible customer sentiments.
In real corporate world , most of the sentiment analysis will be unsupervised. Today we shall discuss one module named VADER ( Valence Aware Dictionary and sEntiment Reasoner ) which helps us achieve this sole purpose.
1. Lets Begin With Action
VADER is an NLTK module that provides sentiment scores based on words used. VADER is intelligent enough to understand negation words like “I Love You” vs “I Don’t Love You” , also not limited to finding sentiments in “wow” vs “wow!!!!” where “!” adds to emotions.
Step 0 : Before we begin , Lets download the dataset to be used from HERE. Also besides NLTK we need to install VADAR NLTK files as shown below.
import nltk. #if not present : pip install nltk
'''
This is how we download vadar files.
'''
nltk.download('vader_lexicon')
Step 1 : Next we shall read the files in pandas dataFrame.
import numpy as np
import pandas as pd
df = pd.read_csv('moviereviews.tsv', sep='\t')
df.head()

Step 2 : Next we manage null values & empty strings.
# REMOVE NaN VALUES AND EMPTY STRINGS:
df.dropna(inplace=True)
blanks = [] # start with an empty list
for i,lb,rv in df.itertuples():
if type(rv)==str:
if rv.isspace(): # test 'review' for spaces
blanks.append(i) # add matching index numbers to the list
df.drop(blanks, inplace=True)
Step 3 : import SentimentIntensityAnalyzer and create a object for future use.
from nltk.sentiment.vader import SentimentIntensityAnalyzer
sid = SentimentIntensityAnalyzer()
Step 4 : Lets get into real action
#use inbuilt sid.polarity_scores to extract scores. Read on for the results
df['scores'] = df['review'].apply(lambda review: sid.polarity_scores(review))
#We break the dict generated above and pull only column 'compound'
df['compound'] = df['scores'].apply(lambda s : s['compound'])
#the step above returns values from -1 to 1.
df['comp_score'] = df['compound'].apply(lambda n : 'pos' if n >=0 else 'neg')
df.head()
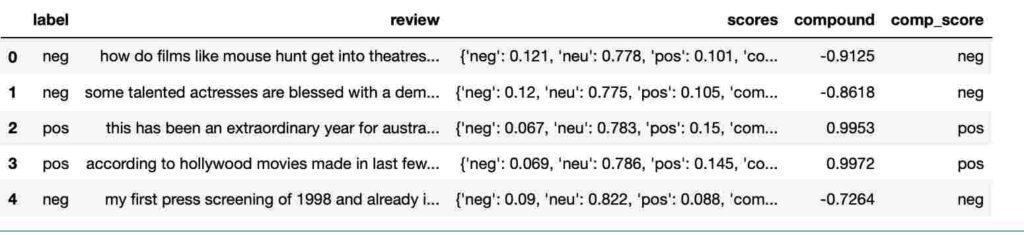
Note 1 : function sid.polarity_scores returns 4 elements :
neg : negative sentiment score.
neu : neutral sentiment score.
pos : positive sentiment score
compound : computed by normalising the scores above.
Note 2 :
negative compound value signifies negative sentiment .
Positive compound value signifies Positive sentiment .
Compound value around zero signifies neutral sentiments.
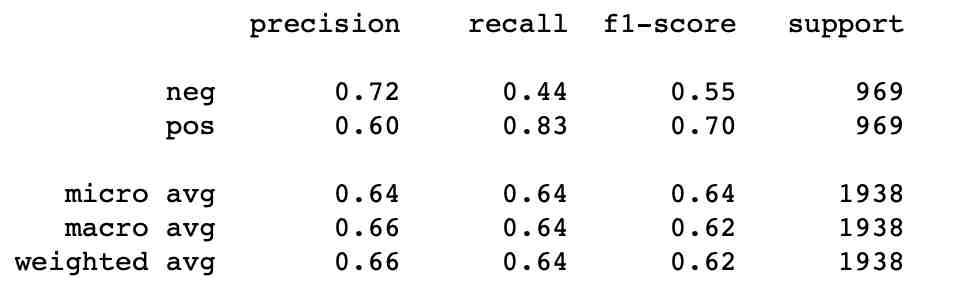
Step 5 : Verify for accuracies using confusion matrix & classification report.
from sklearn.metrics import accuracy_score,classification_report,confusion_matrix
accuracy_score(df['label'],df['comp_score'])
#0.6367389060887513
print(classification_report(df['label'],df['comp_score']))
print(confusion_matrix(df['label'],df['comp_score']))
2. Scope for improvement.
We see the results aren’t very impressive yet. Few of the workarounds we can try to get better results are :
- Try to cleanse the text better.
- Try using stemming and lemmatization and see if it makes a difference.
3. Complete Code
import numpy as np
import pandas as pd
df = pd.read_csv('moviereviews.tsv', sep='\t')
df.head()
# REMOVE NaN VALUES AND EMPTY STRINGS:
df.dropna(inplace=True)
blanks = []
for i,lb,rv in df.itertuples():
if type(rv)==str:
if rv.isspace():
blanks.append(i)
df.drop(blanks, inplace=True)
from nltk.sentiment.vader import SentimentIntensityAnalyzer
sid = SentimentIntensityAnalyzer()
#use inbuilt sid.polarity_scores to extract scores. Read on for the results
df['scores'] = df['review'].apply(lambda review: sid.polarity_scores(review))
#We break the dict generated above and pull only column 'compound'
df['compound'] = df['scores'].apply(lambda s : s['compound'])
#the step above returns values from -1 to 1.
df['comp_score'] = df['compound'].apply(lambda n : 'pos' if n >=0 else 'neg')
from sklearn.metrics import accuracy_score,classification_report,confusion_matrix
accuracy_score(df['label'],df['comp_score'])
#0.6367389060887513
print(classification_report(df['label'],df['comp_score']))
print(confusion_matrix(df['label'],df['comp_score']))
4. Final Say
The module VADER produces some amazing results if we have data clean enough.
Besides this main limitation I observed is , VADER is very poor in identifying if a sentence has mix of positive and negative sentiments. Also VADER is bad in identifying sarcasm too 🙂
Thanks for reading !
You may not want to miss these exciting posts :
- Hashing In Python From Scratch ( Code Included )
 We cover hashing in python from scratch. Data strutures like dictionary in python use underlying logic of hashing which we discuss in detail.
We cover hashing in python from scratch. Data strutures like dictionary in python use underlying logic of hashing which we discuss in detail. - Recursion In Python With Examples | MemoizationThis article covers Recursion in Python and Memoization in Python. Recursion is explained with real world examples.
- Unsupervised Text Classification In PythonUnsupervised text classification using python using LDA ( Latent Derilicht Analysis ) & NMF ( Non-negative Matrix factorization )
- Unsupervised Sentiment Analysis Using PythonThis artilce explains unsupervised sentiment analysis using python. Using NLTK VADER to perform sentiment analysis on non labelled data.
- Data Structures In Python – Stacks , Queues & DequesData structures series in python covering stacks in python , queues in python and deque in python with thier implementation from scratch.




