
Así que estás aquí para correr el riesgo de aprender redes neuronales recurrentes por tu cuenta. Apreciado! Cuando comencé mi viaje para comprender las redes neuronales recurrentes (RNN), honestamente sentí, ¡Oh Dios! sálvame 😀
Este es mi intento de explicarte las redes neuronales recurrentes en términos simples y lo más simple posible para que tú tampoco tengas esa sensación de OMG . Este artículo tendrá redes neuronales recurrentes explicadas en términos simples.
Así que comencemos el viaje que llamo “Redes neuronales recurrentes en pocas palabras” 😛
Alerta distracción: Si usted está fascinado sobre la visión por ordenador y desea aprender las redes neuronales convolucionales en laico términos, ¡uf! Puedes leerlo aquí .
1. ¿Por qué necesitamos redes neuronales recurrentes?
Cuando necesitamos algoritmos para evaluar datos en secuencia / orden , consideramos redes recurrentes porque las redes neuronales artificiales normales y las redes neuronales convolucionales aman evaluar los datos al azar .

Si conocen redes neuronales artificiales (ANN) o redes neuronales convolucionales (CNN), independientemente de los datos que proporcionen a los modelos, no seguirán un orden cuando se evalúen.
Confundido?
Hagámoslo simple.
Imagínese 2 frases: “Me encanta Scarlett Johansson porque es hermosa” y “Me encanta la belleza porque es Scarlett Johansson”.
Aunque la segunda oración no tiene sentido, cuando alimentamos esto a un ANN o CNN, la salida final sería la misma que la posición de las palabras no importa a estos algoritmos.
Ahora imagine que vemos a una chica hermosa y queremos proponerle matrimonio. Nuestra oración debe salir en secuencia como “Te amo” y no al azar . Los RNN ayudan en este caso.
Los RNN se usan mejor en predicciones de existencias , pronósticos del tiempo , etc., donde nuestros pronósticos futuros dependen en cierta medida de los datos anteriores.

2. ANNs Vs RNNs | ¿Qué son las redes neuronales recurrentes?
Las redes neuronales recurrentes son un tipo de redes neuronales que fueron diseñadas especialmente para aquellos datos cuyo futuro depende de su pasado .
2.0 ANN
Bien, así es como se ve una red neuronal normal .
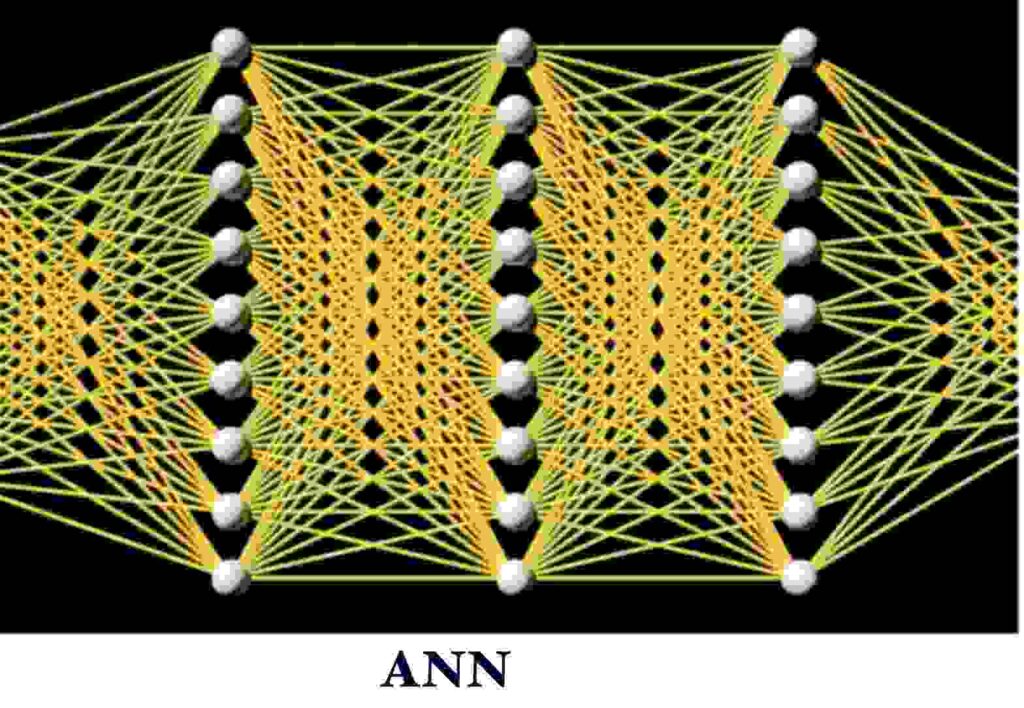
En un ANN normal totalmente conectado Tenemos una capa de entrada , una o varias capas ocultas y una capa de salida .
Nota: Una red neuronal se llama completamente conectada si todos los nodos de una capa están conectados a todos los nodos de la capa siguiente.
Ahora echemos un vistazo a una capa de nodo .
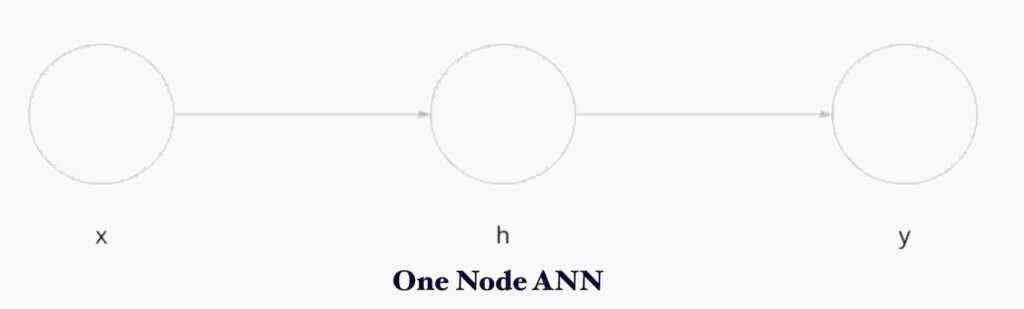
Considere x = entrada , h = nodo oculto , y = nodo de salida . Las fórmulas para los cálculos de salida son las siguientes.
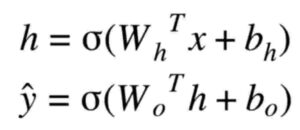
Fórmulas ANN en palabras:
Salida de nodo oculto = función de activación ( Peso del nodo oculto * entrada
PLUS
sesgo del nodo oculto )
Salida final = función de activación ( Peso del nodo de salida * salida del nodo oculto
PLUS
sesgo del nodo de salida )
2.1 RNN en detalle
¡Es hora de ir al grano , comencemos con los RNN !
Las redes neuronales recurrentes son similares a las anteriores pero con una pequeña diferencia . Es decir, tiene un nodo oculto apuntando a sí mismo.
¿Entonces, qué significa esto? La siguiente foto te da una imaginación clara .
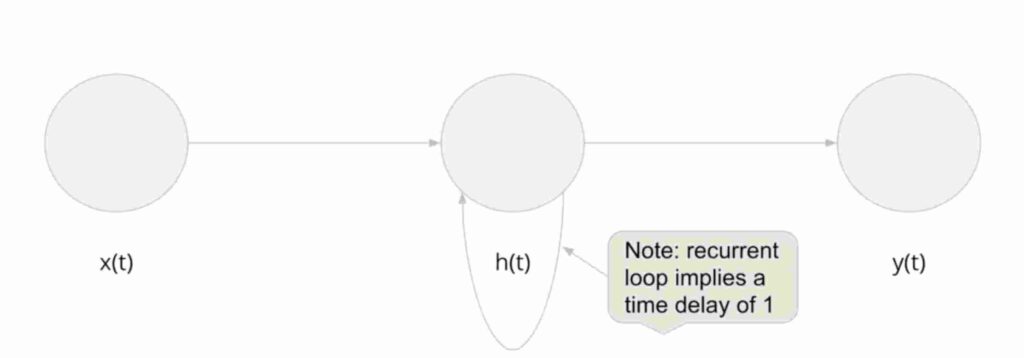
Cuando vemos la foto de ANN ONE NODE arriba, vemos una ligera diferencia. En los RNN, el estado / valor anterior del nodo contribuye a la salida del nodo oculto .
Mira las fórmulas para los cálculos a continuación. ¡Serás mucho más claro !
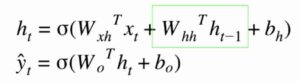
Mire la sección resaltada en verde de las fórmulas. cuando se compara con ANN normal vemos ah (t-1) en la imagen. En términos sencillos, podemos recordar esto ya que la salida del nodo oculto también depende del valor anterior de la capa oculta .
Revise el texto de las fórmulas a continuación para que quede completamente claro.
Fórmulas RNN en palabras:
Salida de nodo oculto = función de activación ( Peso del nodo oculto * entrada
MÁS
Peso del nodo oculto a oculto * Estado del nodo oculto en la iteración anterior
MÁS
sesgo del nodo oculto )
Salida final = función de activación ( Peso del nodo de salida * salida del nodo oculto
MÁS
sesgo del nodo de salida )
Si queremos entender lo que sucede dentro de la capa oculta en los RNN, es sorprendente saber que cada capa oculta en RNN es una red neuronal en sí misma.
¿No confías en mi?
Vea una imagen de la capa oculta de RNN desenrollada .
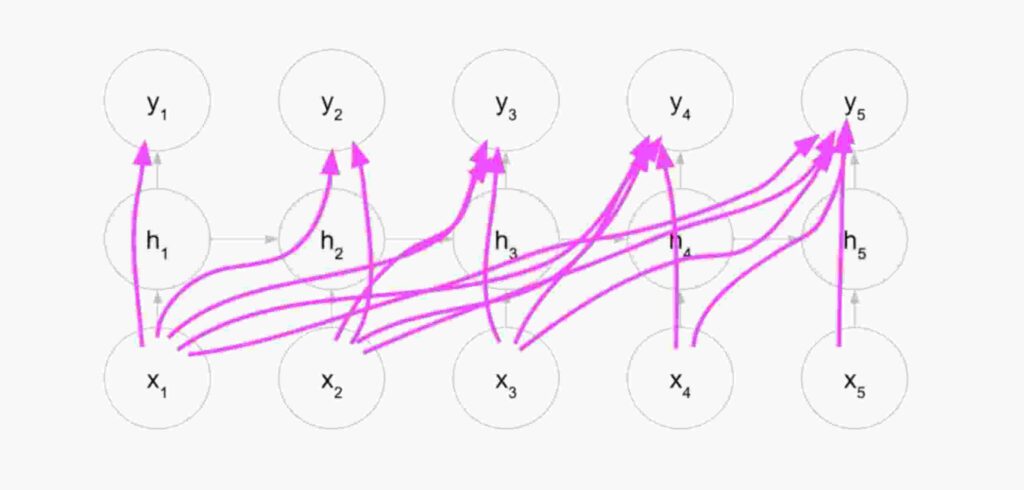
Bueno, ¡no te asustes con tantas conexiones! El pic simplemente nos dice que cada próxima iteración dentro de una capa oculta de RNN será dependiente de los valores de la anterior iteración.
Esto significa que la iteración final h5 dependerá de todas las iteraciones anteriores.
2.2 Pocas fórmulas importantes para recordar

3. Pseudocódigo de redes neuronales recurrentes en Python
Si todas las fórmulas anteriores te asustan , entonces tengo algo de alivio para ti. El código real para RNN es solo algunas líneas de programa a continuación.
El bucle es un RNN en resumen.
Nota: Cuando se trata de RNN, uno siempre debe recordar estas anotaciones .
En la actualidad, todo el trabajo en el backend lo realizan bibliotecas como keras, pytorch. Pero siempre es bueno entender cómo se construyen estas bibliotecas.
- N = número de muestras
- T = longitud de secuencia
- D = número de características de entrada
- M = número de unidades ocultas
- K = número de unidades de salida
3.1 Código RNN simple desde cero
h_last = np.zeros(M) #initial hidden state
x = [1,2,3,4,5] #Tu aportación
Yhats = [] # donde almacenamos la salida
for t in range(T):
#calculamos esto según las fórmulas RNN que vimos anteriormente
h = np.tanh(x[t].dot(Wx) + h_last.dot(Wh) + bh)
# Aunque calculamos esto cada vez, solo nos importa este valor en la última iteración
y = h.dot(Wo) + bo
Yhats.append(y)
# importante: Asigne h a h_last. Aquí es donde giramos ocultos a ocultos
h_last = h
# imprimir la salida final
print(Yhats[-1])
3.2 RNN simple usando Tensorflow
Dar arriba es un código RNN de entrada simple simple . Pero en la vida real si quieres escribir esto usando algún módulo , por ejemplo, tensorflow . Solo escribiríamos:
M = 5 # cantidad de unidades ocultas
i = Input(shape=(T, D))
x = SimpleRNN(M)(i)
x = Dense(K)(x)Eso es una locura, ¿no?
Pero la realidad en el mundo de la ciencia de datos y el aprendizaje automático en la generación actual es que solo debes saber cómo usar los módulos . Conocer las matemáticas detrás de ellos es excelente, pero eso es a menudo subestimado por cualquier aspirante a científico de datos que definitivamente no debería.
4. Principales inconvenientes de RNN y origen de LSTM / GRU
Ahora, considere la siguiente descripción wiki y tenemos RNN para construir un modelo de pregunta y respuesta .
RNN escanea las palabras desde el principio hasta el final y sigue actualizando los pesos (h, h-1, h-2 … hn).
Cuando termine el entrenamiento y RNN esté al final de la oración , imagine que le preguntamos a RNN ” ¿cuál es la fecha de nacimiento de Scarlett Johansson? “.

El RNN probablemente no responderá, ya que la fecha de nacimiento está al comienzo del párrafo y cuando RNN llegue al final actualizando los pesos, es decir (h, h-1, h-2 … hn), las primeras iteraciones no tendrán un peso genuino ¡Todo gracias a un problema de gradiente de fuga del villano !
De acuerdo, hay muchas definiciones de problemas de gradiente, pero intentaré darte una intuición simple.
Mira la imagen a continuación.
4.1 ¿Qué es el problema de gradiente de fuga?
El nodo 1 (x1, h1, y1) comenzaría a leer el párrafo wiki. Se leería secuencialmente como lo hacemos los humanos y cuando complete la lectura, haría 2 cosas.
Uno : Siga actualizando los pesos de los pesos anteriores de (h-1, h-2 ..)
Dos : Continúe leyendo las oraciones.
Ocurre que los pesos de h1, h2, h3 no se actualizan lo suficiente como para reflejar la salida real . Eso ocurre principalmente debido a la propagación hacia atrás de los pesos actualizados utilizando derivados de funciones.
¿Suena demasiado técnico?
Bien, recuerda esto, ya que tenemos 10 chocolates y 7 estudiantes para compartir. Seguimos dando doscada uno desde el final y cuando llegamos a los niños de 4-5 nos damos cuenta de que no hay suficientes chocolates para todos . Por lo tanto, seguimos dando 1 a cada uno de los niños 5.
Aunque no es acertado , esta explicación nos dice que la distribución no es uniforme para los niños 1-7 con menos recursos disponibles para los niños al principio .
De la misma manera, las capas iniciales en la red neuronal no verán un cambio importante en los pesos allí, lo que no traerá mejoras en la capacidad predictiva de ninguna red neuronal.
R\Consulte este cuaderno para una demostración práctica de la Universidad de Stanford sobre problemas de gradiente .
4.2 Aparición de LSTM y GRU
Aunque se sugirió el uso de funciones de activación para reducir los problemas de gradiente en las ANN , no funcionó de manera efectiva en las RNN. La razón principal es el bucle de retorno al nodo oculto actual y las consideraciones de tiempo (t-1) al calcular los siguientes valores.
Aquí apareció una técnica de una década de LSTM y una versión modificada de GRU. Vamos a entender cómo los LSTM y GRU ayudan a manejar mejor los problemas de gradiente .
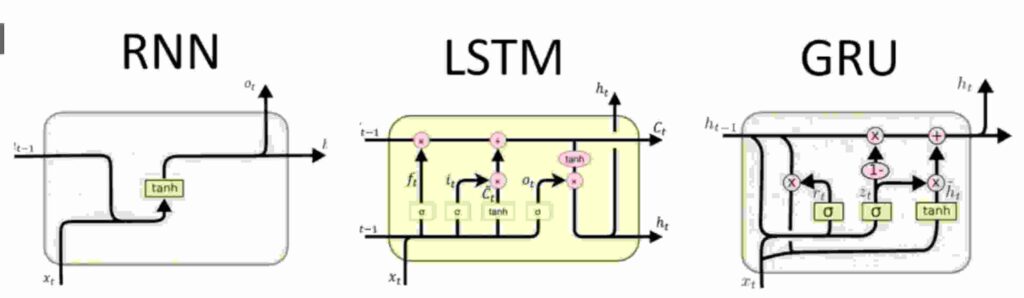
5. LSTM y GRU explicados en términos simples
En caso de que se pierda en alguno de los términos / explicaciones a continuación, o si siente que las cosas se le están pasando por la cabeza , recuerde siempre una cosa.
Cada nodo / puerta / unión / fórmulas que ve en los RNN, sus fórmulas o matemáticas finalmente tienen la misma estructura, es decir,
salida = función_activación ( pesos * entrada + ( pesos * oculto_nodo -1) + sesgo )
En resumen, verifique a continuación.
Es posible que acaba de ver la diferencia en los alfabetos utilizados en la notación , pero confía en mí, todos y cada uno fórmulas a continuación siguen mismas estructuras .
LSTM Soportes para L ong S hort T erm M emory y GRU significa G clasificación de R ecurrent U nits.
Comencemos con los GRU y sus explicaciones matemáticas y simples.
5.1 GRUs
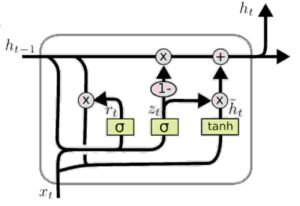
Así que no se asuste con el vínculo de James como el diagrama de arriba.
Una manera fácil de recordar los GRU es que tienen una puerta de memoria para todo lo que hacen. Una puerta cada uno para recordar pesos, olvidar pesos y restablecer pesos.
Verifique las fórmulas a continuación comparando cómo se realizan los cálculos normales de RNN frente a los de GRU . Como destaqué antes, la estructura sigue siendo la misma.

Nuevamente, uno no necesita recordar estas ecuaciones . Pero deje que estas cosas estén en su memoria sobre cómo funcionan las fórmulas anteriores.
Pague a continuación para una ruptura fácil y rápida .
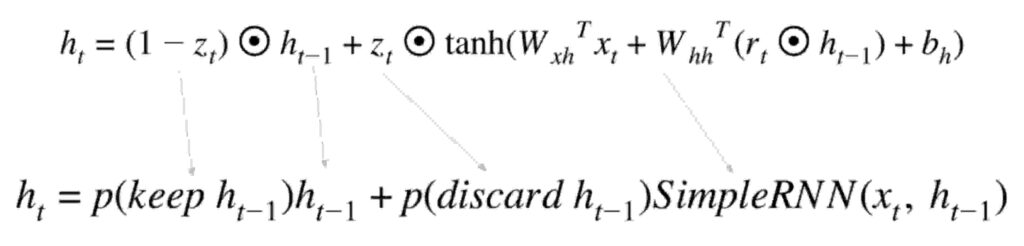
Verías, es así de simple. La ecuación tiene una puerta de mantenimiento y una puerta de descarte . Siga para continuar colocando un peso en la memoria y deséchelo para eliminar los pesos innecesarios. Además, también hay una puerta de reinicio (marque r en la ecuación a la derecha) que restablece los pesos cuando sea necesario.
Pero final del día , como un científico de datos o para un ingeniero ML, cuando nos implementar RNNs o Grus la estructura se mantiene igual que abajo 😀
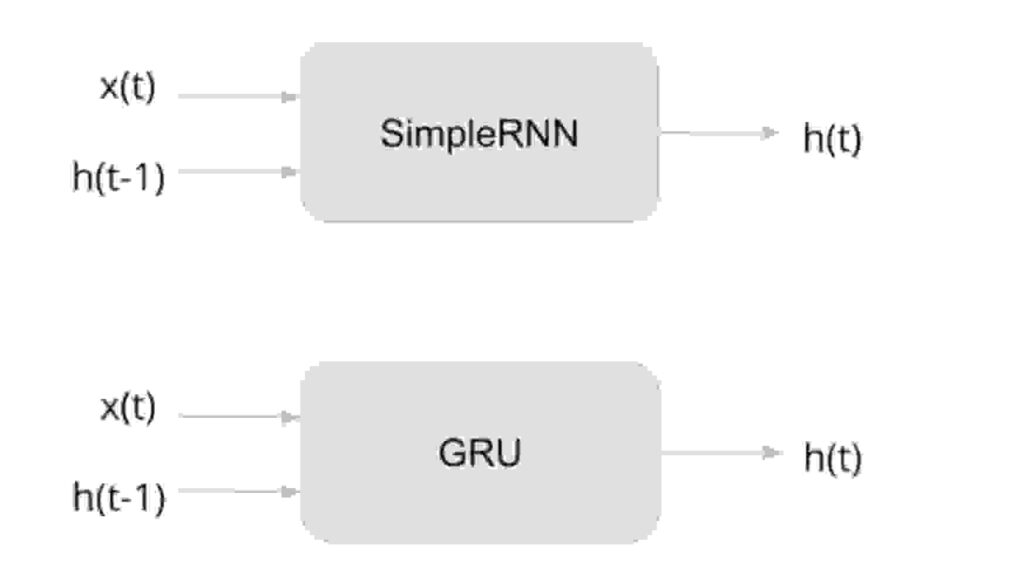
5.2 LSTMs
En primer lugar, la parte de miedo ! ¿Cómo se ve un LSTM ?
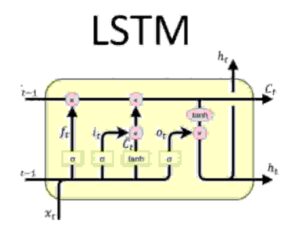
¡No te preocupes , incluso yo no podía entender esto al principio!
Bastante similar a los GRU, LSTM tiene solo algunas características adicionales. Echa un vistazo a la foto de abajo.
Vemos una c adicional (t-1) en los LSTM. Eso no es más que auto estado . Entonces, ahora la predicción no solo depende de x (t) input y h (t-1) estado oculto con el tiempo y también depende de c (t-1) self state .

Entonces, además de estos, LSTM tiene pocos conceptos de puertas .
Las puertas funcionan de la siguiente manera:
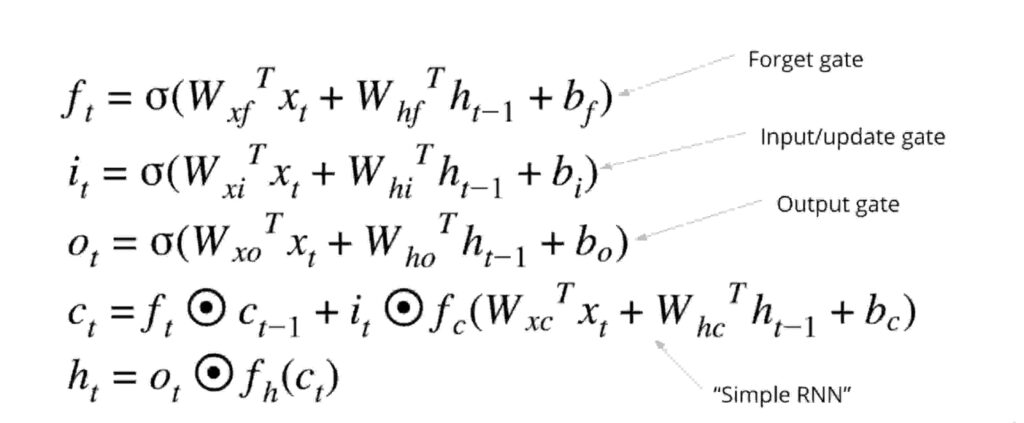
Recuerde , cada puerta tiene un trabajo específico. Los nombres de las puertas lo dicen todo.
Lo más importante que entendimos es que el concepto de GRU & LSTM apareció en la imagen debido a un problema de gradiente que desaparece . es decir, los RNN tenían dificultades para controlar los pesos de todas las neuronas . El concepto de puertas ayuda a gestionar los pesos afectivamente.
Olvídate de las compuertas, las compuertas de entrada / actualización , las compuertas de salida ayudan a mantener pesos relevantes y olvidan pesos no importantes.
Consulte este enlace para mucho másexplicación técnica sobre LSTM y GRU . Mi intento es explicar conceptos principalmente de una manera no técnica y fácil para que pueda volver con algo de aprendizaje y no solo leer este artículo.
Consejo para recordar las matemáticas :
revisa el patrón de todas las fórmulas anteriores.
Todo se parece a :
salida = activación_función ( pesos * input + ( pesos * hidden_node -1) + sesgo )
Entonces, esta debería ser una vista final 🙂 Sé que esto se ve elegante y no ayudará a nadie a entender nada. Pero creo que he mantenido los conceptos lo más simples posible en mi publicación.
6. Final decir
Honestamente , como científico de datos, todo lo que estudiaste hasta ahora se puede implementar en estas pocas líneas de código a continuación.
En una nota más clara , incluso si el 90% de los conceptos que estudiaste te superaron, algunas líneas de código a continuación pueden hacer que cualquiera sea un científico de datos 😛

Concluyendo ,
nos empezamos con RNNs seguido de cómo funcionan. Luego, los inconvenientes y lo que hizo que LSTM y GRU entraran en escena.
Asumiendo que aprendiste algunas cosas increíbles sobre los RNN hoy, en caso de que seas un principiante y sientas que la mayoría de los conceptos se te pasaron por la cabeza , ¡no te preocupes!
Me llevó semanas de esfuerzo comprender los RNN y puede que leas este artículo nuevamente, después de lo cual definitivamente siento que entenderás mejor las cosas.
Una red neuronal aprende mejor después de muchas iteraciones , por lo que 🙂
Este fue un intento de explicar las cosas en simples términos y mantener la complejidad como simples como sea posible.
Gracias por leer !
¡Quizás no quieras perderte estos increíbles artículos!
- Estructuras de datos en Python: pilas, colas y deques
 Series de estructuras de datos en python que cubren pilas en python, colas en python y deque en python con su implementación desde cero.
Series de estructuras de datos en python que cubren pilas en python, colas en python y deque en python con su implementación desde cero. - Estructuras de datos en Python – Arrays | Créalos desde ceroEstructuras de datos en python. Este artículo cubre las matrices en Python y la implementación de matrices desde cero. Esto también cubre la gestión de la memoria de la matriz.
- Redes neuronales recurrentes en pocas palabras | Guía A-Z¿Qué es una red neuronal recurrente? Un tipo especial de redes neuronales, también llamadas RNN, se usa ampliamente para tratar datos de secuencia.
- Redes neuronales de convolución en pocas palabras | Guía de la A a la ZLa red neuronal convolucional (ConvNet o CNN) es una red neuronal utilizada de manera efectiva para el reconocimiento y clasificación de imágenes. CNN no es menos que una caja mágica
- Clasificación lineal (regresión logística) utilizando reciente Tensorflow 2+En este artículo, implementamos la clasificación lineal utilizando la versión más reciente de Tensorflow. es decir, 2.2+ ¿Qué es la clasificación lineal ? Cuando los puntos de datos a clasificar son separables por una línea o, en términos más fáciles, podemos trazar una línea entre los registros de éxito y los registros de falla, lo llamamos Clasificador lineal . … Read More »Clasificación lineal (regresión logística) utilizando reciente Tensorflow 2+



