En este artículo, implementamos la clasificación lineal utilizando la versión más reciente de Tensorflow. es decir, 2.2+
¿Qué es la clasificación lineal ?
- Cuando los puntos de datos a clasificar son separables por una línea o, en términos más fáciles, podemos trazar una línea entre los registros de éxito y los registros de falla, lo llamamos Clasificador lineal .
En el campo de la ciencia de datos o el aprendizaje automático , un clasificador lineal tiene un objetivo de clasificación estadística para identificar a qué clase de salida pertenece un conjunto de entrada.
Al usar valores de combinaciones lineales y tomar una decisión de clasificación , un clasificador lineal logra su objetivo final.
Los ejemplos de clasificador lineal incluyen regresión logística , clasificación NB , etc.
¿Cuál es la diferencia entre las técnicas de clasificación lineal y no lineal?
Para el espacio de entidades 2D , digamos datos que tienen solo el eje xy el eje y. Si se puede dibujar una línea entre puntos sin cortar ninguno de ellos, son linealmente separables .
Ahora, mira la imagen de abajo (a tu derecha). Los casos en los que los datos no son separables utilizando una línea recta se incluyen en la categoría no lineal . Aquí necesitábamos un círculo para separar los puntos.
Lo mismo ocurre con los clústeres en datos 3D . La única diferencia es que se usa un plano allí en lugar de una línea.
Este tipo de clasificador funciona mejor cuando el problema es lineal separable.

¿Cuáles son los tipos de diferencia de clasificadores lineales?
Principalmente dividido en:
A: Generativo (asume funciones de densidad condicional):
A1: Análisis discriminante lineal (LDA): asume modelos de densidad condicional gaussiana
A2: clasificador Naive Bayes con modelos Bernoulli multinomiales o multivariados .
B: modelos discriminatorios
(intentos de maximizar la calidad del resultado en un conjunto de entrenamiento)
B1: regresión logística
B1: perceptrones
B1: Máquinas de vectores de soporte (SVM)
- El siguiente truco nos muestra cómo podemos implementar un clasificador lineal usando la famosa biblioteca de tensorflow.
- Este código también demuestra cómo podemos guardar el modelo y usarlo en producción.
| Versión de Python | nivel de dificultad | Requisito previo |
| 2.7+ | fácil | fundamentos de python |
(array(['malignant', 'benign'], dtype='<U9'), array(['mean radius', 'mean texture', 'mean perimeter', 'mean area', 'mean smoothness', 'mean compactness', 'mean concavity', 'mean concave points', 'mean symmetry', 'mean fractal dimension', 'radius error', 'texture error', 'perimeter error', 'area error', 'smoothness error', 'compactness error', 'concavity error', 'concave points error', 'symmetry error', 'fractal dimension error', 'worst radius', 'worst texture', 'worst perimeter', 'worst area', 'worst smoothness', 'worst compactness', 'worst concavity', 'worst concave points', 'worst symmetry', 'worst fractal dimension'], dtype='<U23'))
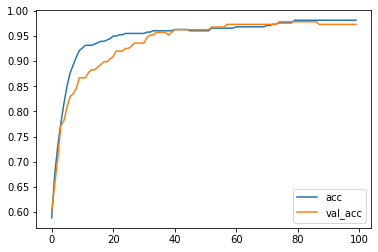
Epoch 100/100 12/12 [==============================] - 0s 4ms/step - loss: 0.0855 - accuracy: 0.9816 - val_loss: 0.1101 - val_accuracy: 0.9734 Test score: [0.10941322147846222, 0.9734042286872864] 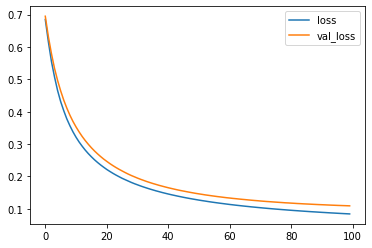
Vamos a usar este modelo para hacer predicciones
Manually calculated accuracy: 0.973404255319149 6/6 [==============================] - 0s 2ms/step - loss: 0.1094 - accuracy: 0.9734 Evaluate output: [0.10941322147846222, 0.9734042286872864]
Vamos a guardar este modelo para implementarlo en producción
model.save ( ‘linearclassifier.h5’ )
-rw-r--r-- 1 root root 18480 Jun 5 07:41 linearclassifier.h5 Podemos optimizar este modelo para obtener una mayor precisión cambiando valores como épocas,
número de capas ocultas, etc.
Todo es un juego de trail y error.
”’
[<tensorflow.python.keras.layers.core.Dense object at 0x7fd15925eb38>] 6/6 [==============================] - 0s 2ms/step - loss: 0.1094 - accuracy: 0.9734
[0.10941322147846222, 0.9734042286872864]