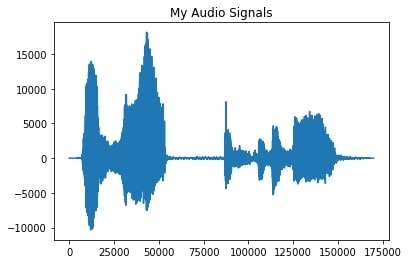
”’
Let’s overwrite some indexes of audio & create a new echo
”’
modified_audio = np.zeros(48000)
#modified_audio[0] = 1. Try uncommenting these and see the difference
modified_audio[14000] = 0.1
#modified_audio[18000] = 1
#modified_audio[22000] = 1
#modified_audio[46000] = 1
#modified_audio[47800] = 1
modified_audio = np.convolve(audio, modified_audio)
modified_audio = modified_audio.astype(np.int16)
write(‘modified_audio2.wav’, 48000, modified_audio)
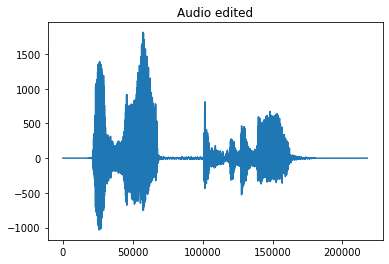
plt.plot(modified_audio)
plt.title(“Audio edited”)